


How do Message Queues work? Not like this!
We need proper "Messaging 101" information out there

Every developer in the world has been introduced to databases during their training, and they have at least a grasp on how a database work and its internals.
I wish we could say the same for messaging.
I have done my good share of “Messaging 101” meetings with developers that never used messaging before, and I do those happily. But I always end with that lingering sensation that it would be better if they have been at least introduced to this topic for some time; instead, they are learning about messaging at the beginning of a sprint with the hope they will be sending and receiving messages ASAP, with no time to get a good understanding of the messaging patterns.
So, I’m very happy when I see people sharing resources that introduces messaging concepts to the general public. But as most people is unfamiliar with this topic, sometimes misleading information is shared to a public that is not ready to know if that information is good or it should be, at least, double checked.
As an example, let’s take a look to this image I have seen shared in LinkedIn several times in the last weeks:
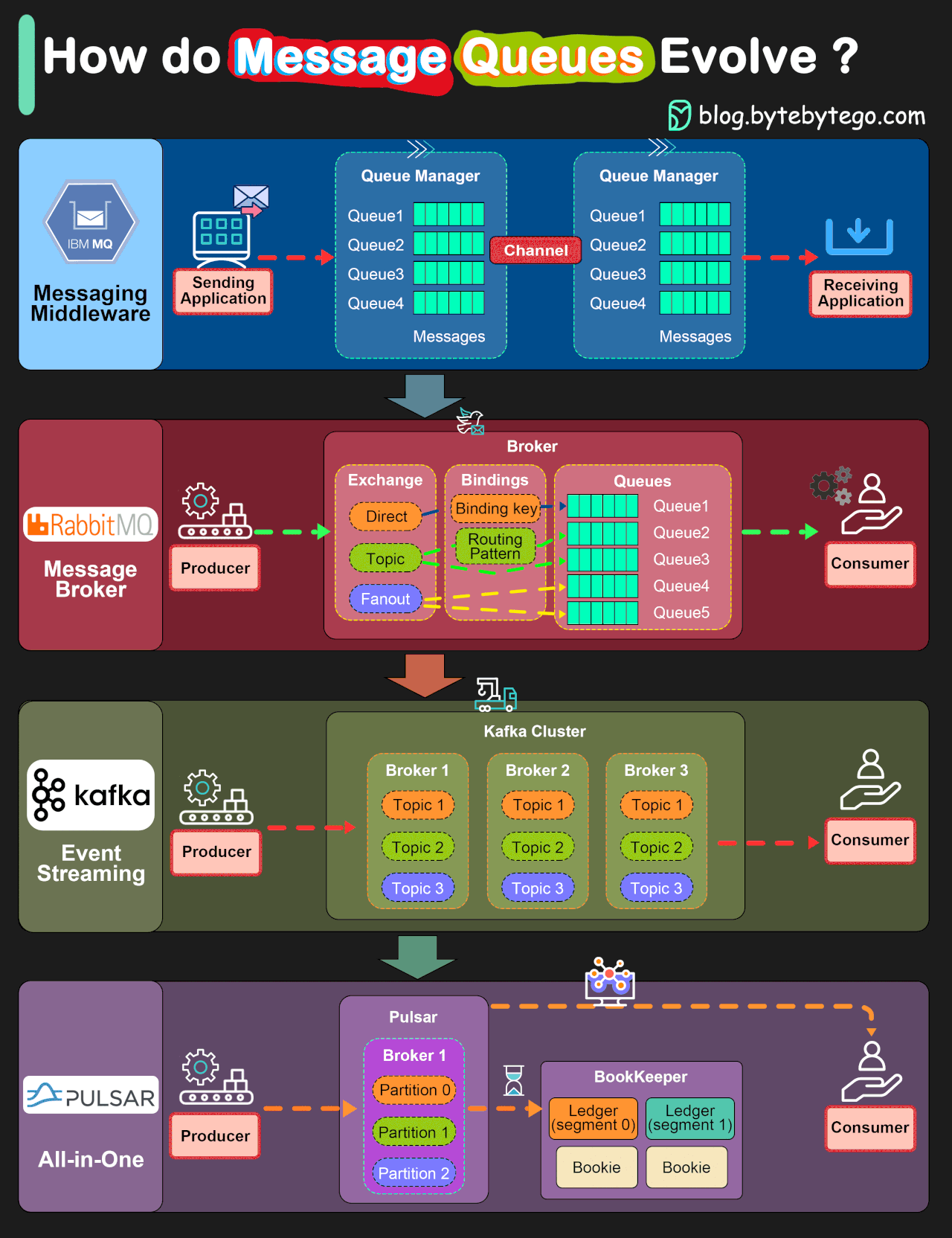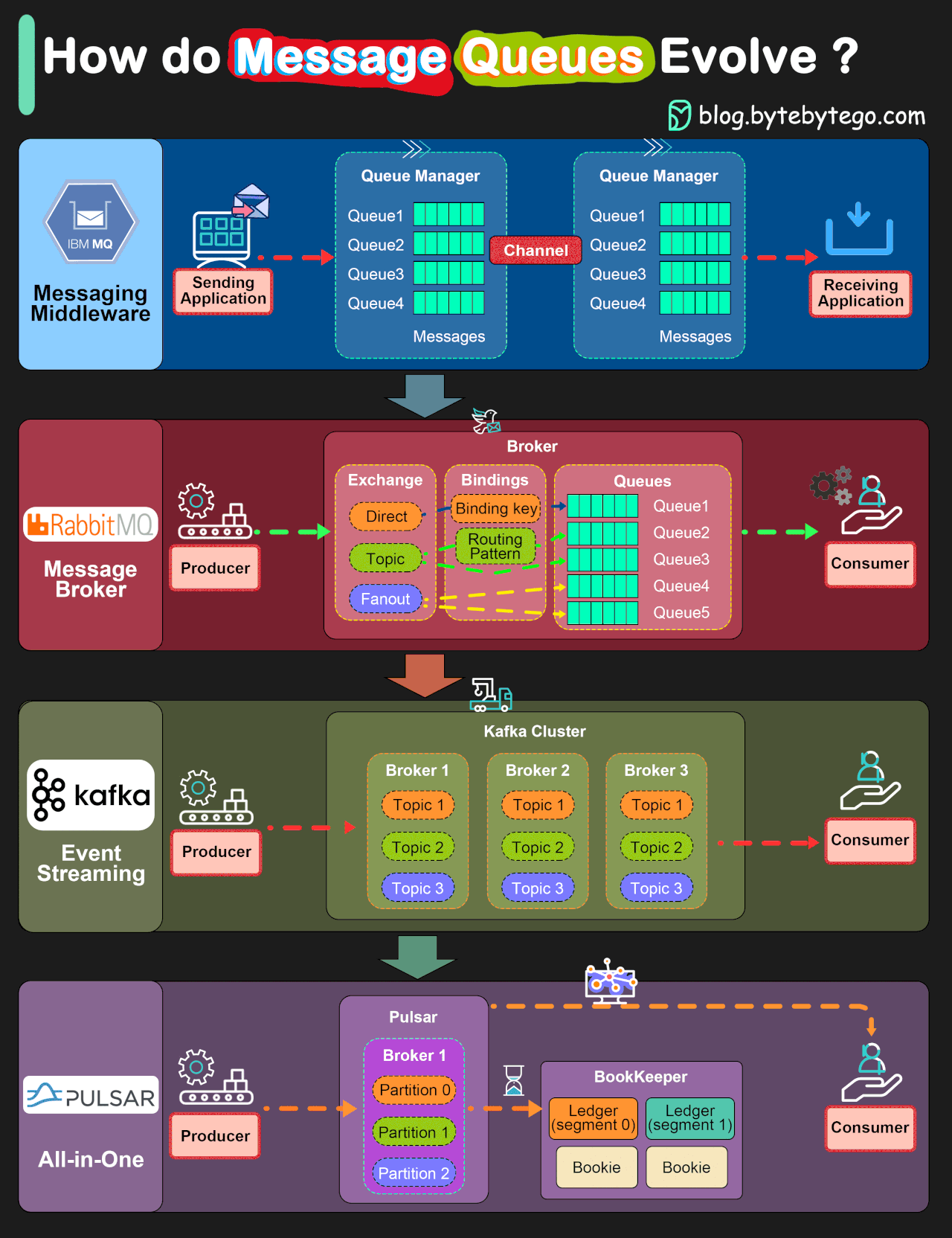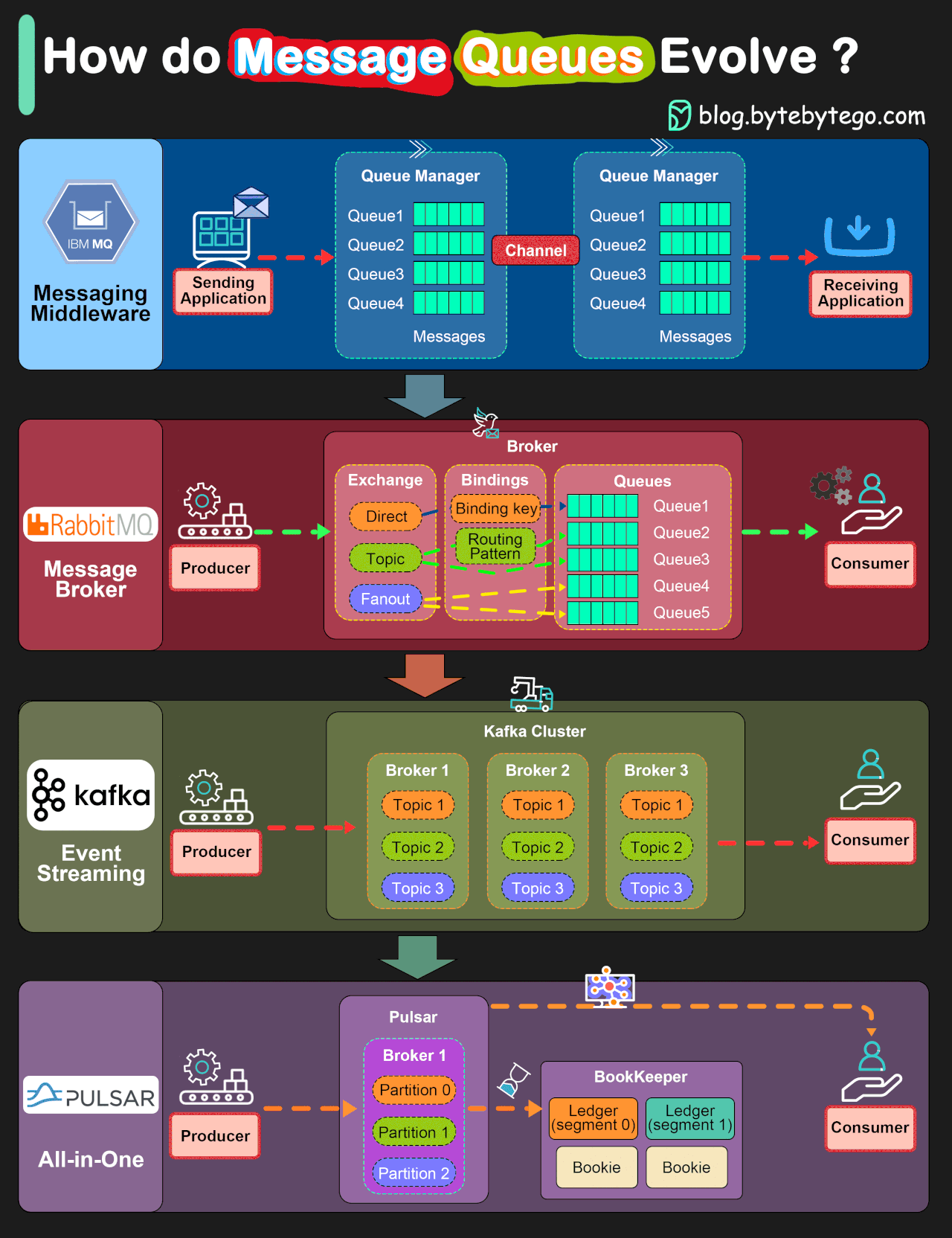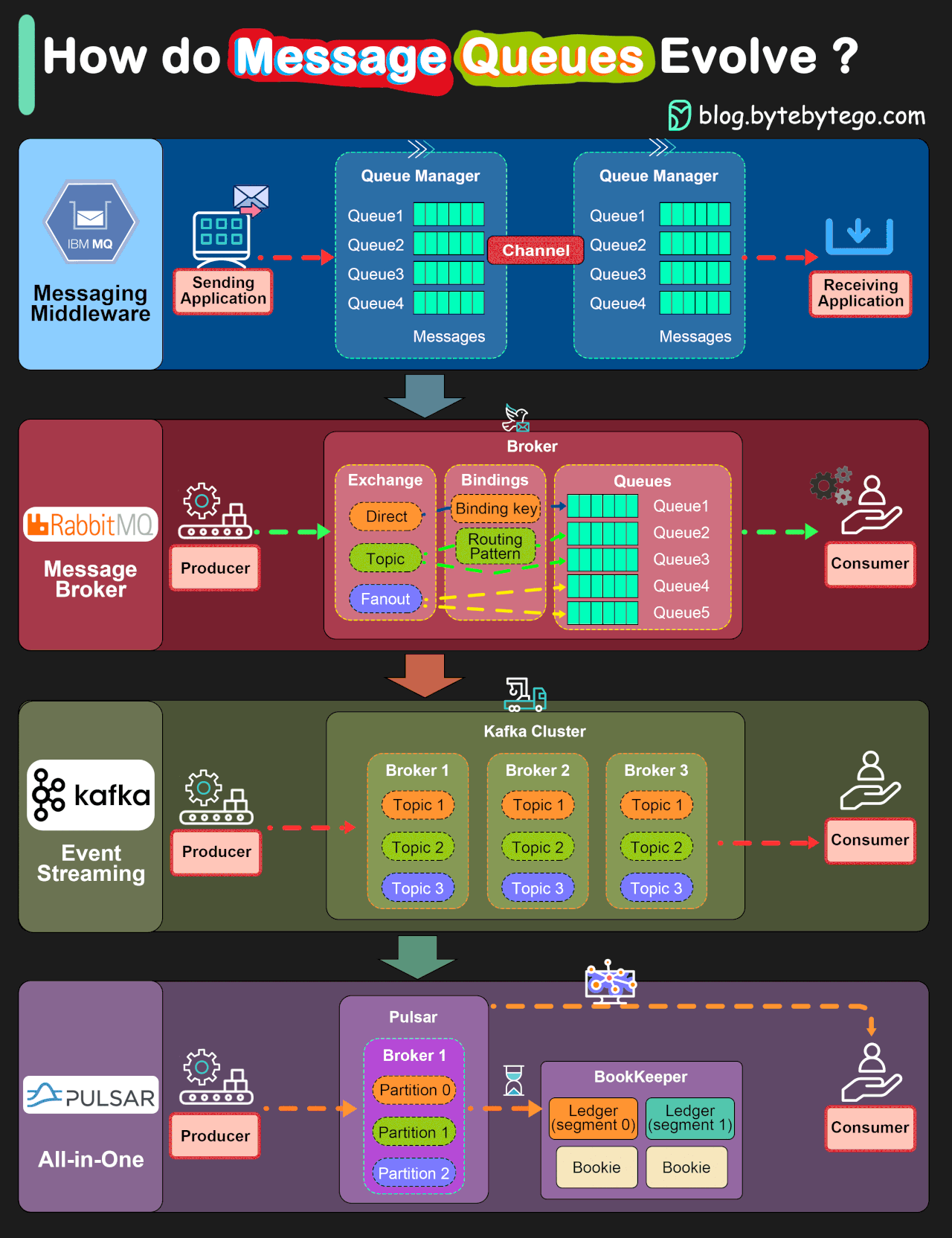
Looks nice, right? So much information in just 1200 x 1600 pixels! This is a great resource to explain things to people!
The problem is, most on the information in that image is either wrong or misleading.
The title and the way the information is presented clearly tries to make the reader think that Pulsar is better than Kafka, Kafka is better than RabbitMQ, and IBM MQ is like the MS-DOS of the messaging world.
And this is done through some graphs explaining how each of these software works.
But those graphs don’t represent how these software works at all!
Those graphs represent different messaging models, and linking each software to one of those models is again misleading. As it is to order them in a way that makes the reader think the older models are superseded by the new ones. Spoiler alert: they aren’t.
First, we have direct messaging, linked to IBM MQ. You can think of direct messaging as something somewhat similar to email: you send a message to an email address, or in this case a queue, the receiver downloads it and remove it from the mail server.
Second, we have RabbitMQ, where it shows it can send direct messages as IBM MQ, as well as being able to use “topics” and “fanouts”. What they are showing here, in reality, is the good old publish-subscribe messaging pattern (more commonly called pubsub). Remember the usenet news groups? Pubsub is a lot like that. Let’s say Jon wants to receive news about MacOS, so he subscribes to computer.os.macos . Fatima is more into Linux, so she subscribes to computer.os.linux . Glen likes to tinker with different OSes on his free time, so he subscribes to computer.os.* to get all messages. So, if I send a message to computer.os.macos , both Jon and Glen will receive each one a copy of the message. If I send a message to computer.os.linux , it will be Glen and Fatima the ones to receive each one a copy of the message. If I send a message to computer.os.windows only Glen will receive the message, and if I send a message to computer.hardware.vga , no one will receive it as noone is subscribed.
I say “receive each one a copy” for a reason. If this was direct messaging, and Glen and Fatima were listening to the same queue, only one of them would receive the message. This is used sometimes as a load balancing strategy, in example you have several instances of your application running in different nodes of a cluster, all reading from the same queue, so the workload of processing the messages is distributed along all the nodes. On pubsub, each one will receive a copy of the message. Combining both leads to very rich possibilities on how to route and consume messages.
That image makes you think that RabbitMQ supports pubsub and IBM MQ doesn’t, right? Well, IBM implemented pubsub in 1997, more than ten years before RabbitMQ existed.
The truth is, RabbitMQ and IBM MQ supports both direct and pubsub messaging paradigms, and based on years of experience, I would say both support these messaging models exceedingly well. There are differences between implementations, but those details are far beyond what a “Messaging 101” graph or text should delve into.
Third, we have Kafka and its streams. I will keep this short, as I’m far from an expert on Streams. Streams are a very different beast: they don’t have many message routing capabilities, but they have very high throughput. Contrary to direct messaging and pubsub, streams store the information in the message broker for some time, and consumers can go back and replay a message received some time ago.
This is the opposite to traditional message models, where using the broker as a message storage system is frowned upon; in traditional message models the broker should hold a message only the minimum needed time to warrant its delivery, and a broker with queues holding many unread messages for a long time is a symptom of either bad design or bad status of the broker. Streams are the opposite to this, and I confess that in my head I tend to think about streams as some kind of database/storage with a pubsub interface. Yeah, I know.
So, we have Kafka, that doesn’t provide traditional messaging, but it is the way to go if you want streams, right? Well, the thing is, RabbitMQ also provides streams. Not only it supports them, the performance is very good, and it even have some nice tricks, like letting consumers using traditional messaging being able to read messages from the stream.
So, once again, the graph was completely misleading.
Finally, we have Pulsar. I have no clue about Pulsar. I have been “the messaging guy” since 2017 in several companies, and noone ever mentioned Pulsar in a meeting, a project, a conference or anywhere else. It seems to be a streams implementation with the graph exposing some of the internals on how it manages storage to make it look different to what it shows for Kafka. But at this point I’m so tired of analyzing this graph, I’ll leave trying to learn a little more about Pulsar for another day.
Each of these patterns have their own use cases, and none is obsolete.
There is no one-size-fits-all solution when it comes to messaging, and knowing these patterns well is key to a proper implementation that really suits your needs without frictions.
That’s all from me, but I would like to hear from you. What is your experience with “Messaging 101”? Do you have any great documentation you would like to recommend? Do you think someone exists that can explain AMQP 1.0 in less that a hundred pages? I don’t 😅, but please prove me wrong: I’ll need to understand AMQP 1.0 sooner or later.
Until the next one,
Carlos A. Balseiro